Transcribing Grothendieck's Handwriting with AI
How I discovered 18,000 pages of scanned handwritten mathematical manuscripts and checked if they can become readable with modern AI
The Mathematician’s Mathematician
 Alexandre Grothendieck in 1951, 1965, and 2014. Photos by Paulo Ribenboim, Karin Tate, and Peter Badge (via Privatdozent).
Alexandre Grothendieck in 1951, 1965, and 2014. Photos by Paulo Ribenboim, Karin Tate, and Peter Badge (via Privatdozent).
During my mathematics degree at the University of Groningen, one name kept surfacing with an almost mythical quality: Alexandre Grothendieck. I knew his work on algebraic geometry and category theory was foundational—the kind of mathematics that other mathematicians build their entire careers upon. But I didn’t know much about the man himself.
Grothendieck (1928–2014) was born to anarchist parents who left him to spend most of his formative years with foster families. His father was murdered in Auschwitz. As his mother was detained, he grew up stateless, hiding from the Gestapo in occupied France. All the while, he taught himself mathematics from books—and before his twentieth birthday had independently re-discovered a proof of the Lebesgue measure, a cornerstone of integration theory.
Later, as a rising star in the French mathematical world of the 1950s and 60s, Grothendieck moved from subject to subject during his “golden years” (1955–1970), introducing revolutionary ideas wherever he went. Then he walked away. To protest against the Vietnam War, he gave lectures on category theory in the forests surrounding Hanoi while the city was being bombed.1
Labatut and the Fiction-Reality Boundary
It wasn’t until I read Benjamin Labatut’s When We Cease to Understand the World that I glimpsed the person behind the theorems. Labatut’s book is a work of fiction—or rather, fiction woven around historical figures, blurring the line between what happened and what might have happened.
The chapter on Grothendieck was haunting. A man who revolutionized mathematics, then retreated from academic life entirely. A pacifist who walked away from prestigious positions over military funding. A recluse who spent his final decades in a small village in the Pyrenees, filling notebooks with what he called “La Clef des Songes” (The Key to Dreams).
But how much of it was true?
Down the Wikipedia Rabbit Hole
I went to Grothendieck’s Wikipedia page to separate fact from Labatut’s imagination. Most of the broad strokes were accurate. The mathematical revolution. The political awakening. The withdrawal.
And then I found something unexpected: the archives.
After Grothendieck died in 2014, his family donated roughly 28,000 pages of handwritten manuscripts to the University of Montpellier. These weren’t just mathematical notes—they were diaries, philosophical reflections, and yes, “La Clef des Songes.”
The archives are available online at grothendieck.umontpellier.fr.2
I downloaded all 146 available PDFs. Four gigabytes of scanned pages. And then I tried to read them.
The Problem: Genius-Level Illegibility
Grothendieck wrote in French, often mixing dense mathematical notation with philosophical prose. His handwriting is… challenging.
 A relatively simple page: a table of contents for functional analysis topics. Even here, crossed-out text and abbreviations make transcription non-trivial.
A relatively simple page: a table of contents for functional analysis topics. Even here, crossed-out text and abbreviations make transcription non-trivial.
 A more typical page (p.145 from document 119): category theory with multiple layers of annotation, margin notes, and Grothendieck’s characteristically dense notation.
A more typical page (p.145 from document 119): category theory with multiple layers of annotation, margin notes, and Grothendieck’s characteristically dense notation.
Even for French-speaking mathematicians, deciphering these manuscripts is slow, painstaking work. The Centre for Grothendieckian Studies (CSG) has been manually transcribing them, but it’s a multi-year effort requiring deep mathematical expertise.
I wondered: could modern AI help?
The Experiment
Vision-language models (VLMs) have improved dramatically in the past year. Gemini, GPT, and Claude can all process images and text together. They’re trained on massive amounts of handwritten text and mathematical notation.
I built a simple pipeline:
- PDF to images: Convert each page to a PNG at 150 DPI
- VLM transcription: Send the image to a model with a prompt asking for faithful transcription in LaTeX
- Output: Store JSON (with metadata) and plain LaTeX files
The prompt was minimal:
Can you extract the text from this?The real question was: how good would the results be?
Results: Comparing the Models
I tested three frontier models on the same pages from document 119 (one of the manuscripts the CSG is actively transcribing):
| Model | Transcription Quality |
|---|---|
| Gemini 3 Pro | ⭐⭐⭐⭐ |
| Claude Opus 4.5 | ⭐⭐⭐ |
| ChatGPT 5.2 | ⭐⭐ |
Test 1: Table of Contents Page (Simpler)
This page lists functional analysis topics (N°1 through N°7): rearrangements of functions, Weyl functions, spectral measures, determinants, operator ring inequalities.
Gemini 3 Pro:

Gemini provided:
- Full French transcription
- English translation
- Notes on the handwriting identifying crossed-out sections
- Mathematical context (noting $(A \in \bar{a})$ refers to operator algebra membership)
Claude Opus 4.5:

Claude produced clean output with proper strikethrough notation for crossed-out text, structured formatting, and topic identification. Slightly less contextual analysis than Gemini.
Test 2: Dense Category Theory Page (Harder)
This is page 145 from document 119—dense category theory with multiple layers of annotation, margin notes, and corrections.
Gemini 3 Pro:
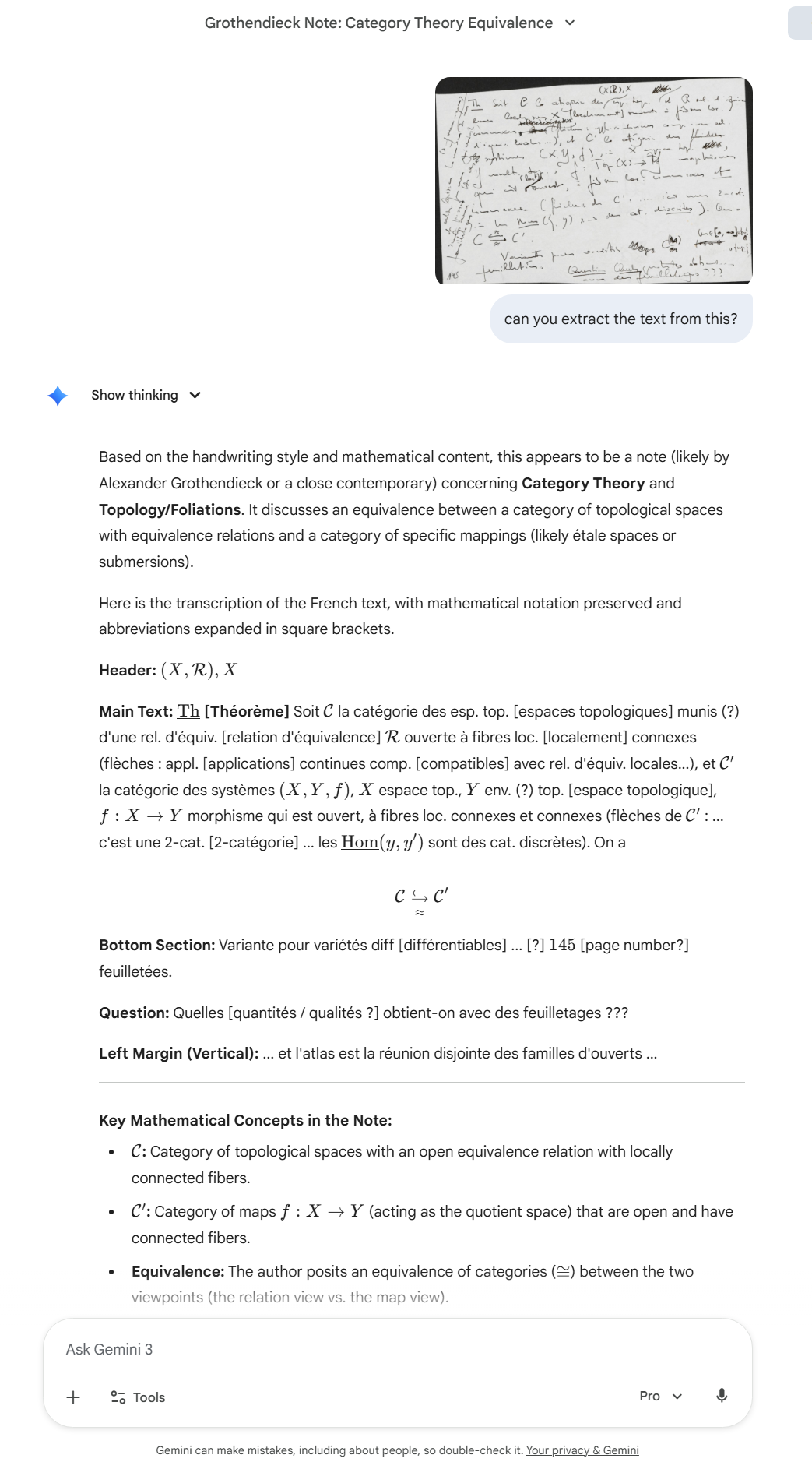
Gemini handled this impressively:
- Identified the mathematical content (category equivalence between topological spaces and specific mappings)
- Preserved LaTeX notation: $\mathcal{C}$, $f: X \to Y$, $\underline{\text{Hom}}(y, y’)$
- Caught the equivalence statement: $\mathcal{C} \rightleftarrows_{\approx} \mathcal{C}’$
- Noted the question at the bottom: “Quelles quantités/qualités obtient-on avec des feuilletages ???”
- Read the vertical margin text
ChatGPT 5.2 Thinking:
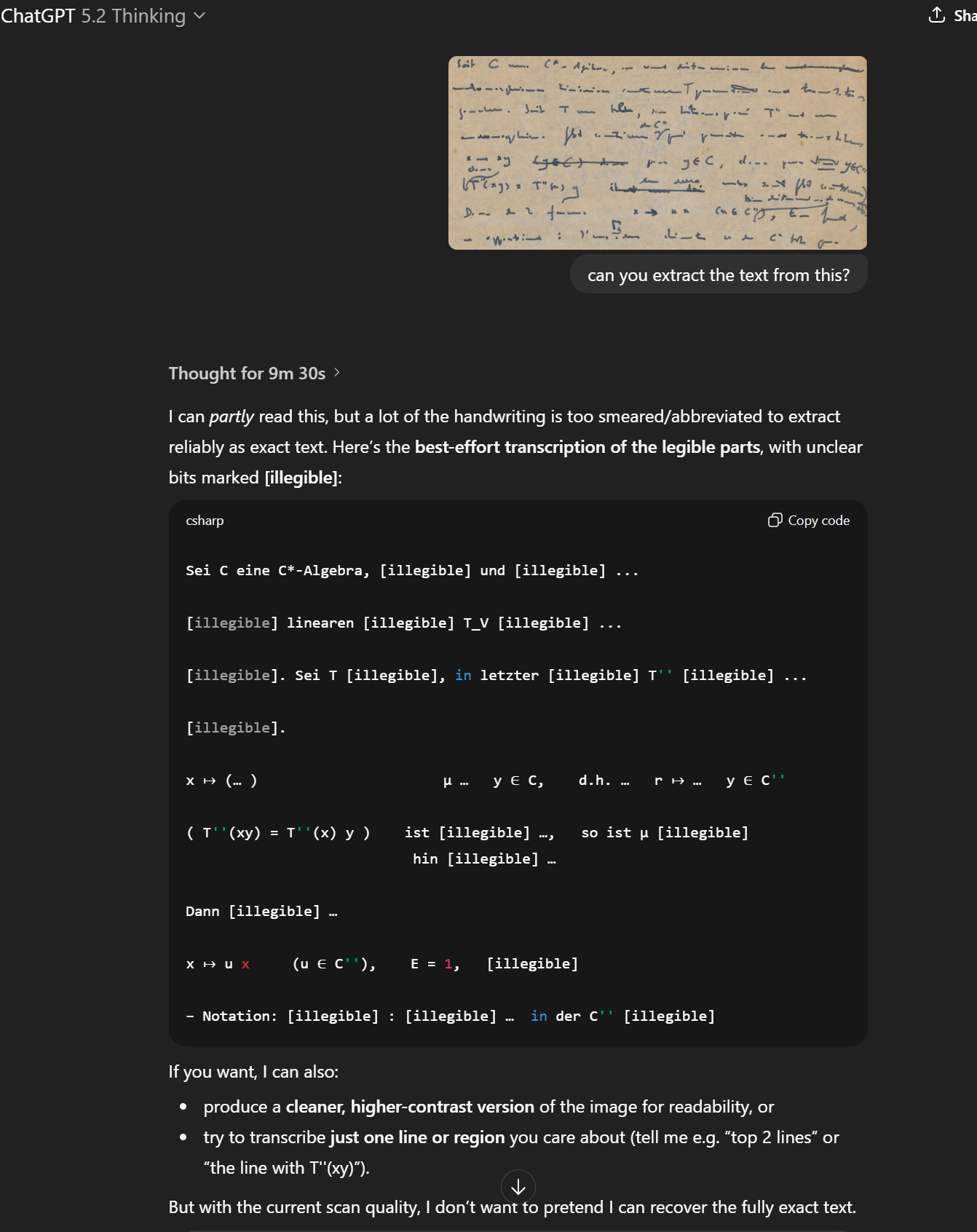
ChatGPT (on a similarly difficult page) struggled significantly:
Sei C eine C*-Algebra, [illegible] und [illegible] ...
[illegible] linearen [illegible] T_V [illegible] ...Many [illegible] markers. The model was honest about its limitations—“I don’t want to pretend I can recover the fully exact text”—but produced much less usable output.
The Verdict
Gemini 3 Pro handles even the most challenging pages with remarkable accuracy. It provides not just transcription but understanding—identifying mathematical concepts, translating, and noting structural features like crossed-out text.
Claude Opus produces clean, well-formatted output and is honest about uncertainty, but offers slightly less mathematical context.
ChatGPT 5.2 struggles with difficult handwriting and is more conservative, resulting in less complete transcriptions. It also took nearly 10 minutes per page compared to roughly 1 minute for Gemini and Claude.
A Note on “Understanding” vs. Confabulation
Something striking: the models recognize this is Grothendieck’s work without being told. The prompt was simply “Can you extract the text from this?”—yet Gemini’s output begins with “This transcription covers the handwritten notes from page 145 of Grothendieck’s archives.” The model inferred the author from handwriting style, mathematical content, and perhaps document structure.
This cuts both ways. The same pattern-matching that enables recognition can produce confident-sounding confabulation. Some of what the models output is likely correct; some is probably hallucinated, especially for heavily crossed-out or ambiguous passages. The models don’t always mark uncertainty.
For transcription work, this is still enormously helpful—a human expert proofreading AI output is far faster than transcribing from scratch. But it means every transcription needs verification, not just spot-checking. A systematic cross-check with domain experts would help quantify the accuracy and could develop into more structured collaborative work between AI and human transcribers.
What I Learned
- Vision LLMs are surprisingly good at handwritten text—even challenging scripts like Grothendieck’s
- Model choice matters enormously—Gemini 3 Pro significantly outperformed alternatives on difficult pages
- Mathematical notation is the hardest part—but top models handle it better than I expected
- The bottleneck isn’t AI, it’s verification—you still need domain experts to confirm correctness
I’m currently reaching out to the Istituto Grothendieck to learn more about their interest in AI-assisted transcription and to better understand the actual accuracy of these outputs against expert transcriptions.
Try It Yourself
The transcription code is open source: github.com/ivan-gentile/grothendieck-ocr
pip install -r requirements.txt
python transcribe.py 119.pdf --model gemini-flash --pages 1-10The archives themselves are freely available at grothendieck.umontpellier.fr.
If you work on mathematical manuscript transcription or OCR for handwritten text, I’d love to hear from you. Reach out on LinkedIn.
Related Reading
- CSG Transcriptions - the manual transcription project
- When We Cease to Understand the World - Labatut’s brilliant book
- Olivia Caramello’s paper on Topos - for the mathematically inclined (added to my personal reading list!)
Co-written with Claude Opus 4.5
Footnotes
-
This remarkable fact comes from his Wikipedia page. ↩
-
The Montpellier website has an expired SSL certificate, so your browser may warn you. The site is legitimate—it’s maintained by the university library. The Istituto Grothendieck in Piedmont, Italy also links to it from their transcription project at csg.igrothendieck.org. ↩